

What is MRA?
The Multidimensional Relational Algebra, or MRA, is at the core of everything we do at Precog. It’s what enables our product to provide such a smooth and intuitive user experience. It’s what drives the ahead-of-time optimizations and static analyses which ensure that transformations are evaluated with extremely high performance as close to the data as possible. It is, in a very real sense, our “secret sauce”. Which is precisely why we have open-sourced the compiler and published this blog post describing how it all works!
What Are “Dimensions”?
The most important element of MRA is right in the name: multidimensionality. If you read this and immediately start thinking of cubing engines then you’re on the right track! To see what this really means though, we need to build some conceptual groundwork.
Consider the following CSV dataset:
first,last,city
Daniel,Spiewak,Boulder
Jeff,Carr,Arvada
Becky,Conning,Manchester
CSV conveniently represents data in a highly tabular format, so it’s easy to see this in terms of a two-dimensional grid. The first dimension is simply the columns: first, last, and city. The second dimension is the rows. As in most data formats, the row dimension is the one which is allowed to extend arbitrarily. We can have any number of rows, but only a set number of columns, chosen on the first line of the file. This observation (the unique nature of the row dimension) is critical and we’ll come back to it.
All relational databases follow this same model. Tables are two-dimensional entities with a fixed set of columns (usually constrained by a static schema) and an unfixed set of rows, each conforming to the set of columns. Unfortunately, this model proves quite insufficient when working with data formats which have nested structure.
For example:
{ “first”: “Daniel”, “last”: “Spiewak”, “emails”: [“[email protected]”, “[email protected]”] }
{ “first”: “Jeff”, “last”: “Carr”, “emails”: [“[email protected]”] }
{ “first”: “Becky”, “last”: “Conning”, “emails”: [ ] }
We can try to fit this dataset into a two-dimensional model by considering each of the array indexes as their own column. For example:
first,last,emails[0],emails[1]
Daniel,Spiewak,[email protected],[email protected]
Jeff,Carr,[email protected],
Becky,Conning,,
This is really awkward though. Even just on the surface, it suffers from several serious issues. For example, the two-dimensional representation is capable of representing nonsensical arrays, such as the following rearrangement of Jeff’s row:
Jeff,Carr,,[email protected]
This is saying that Jeff’s emails array has one element in it, and that one element is in the… second index? It doesn’t make any sense.
Another problem here is that we completely lack the ability to extend the length of the emails; every row has exactly two of them, where either or both of them may be undefined. We can’t easily accommodate an additional row which has three emails. In theory, the set of emails within a given row really should be just as extensible as the set of rows itself, but since the set of columns is fixed, we don’t really have that option. Related to this is the fact that we would probably run into very serious performance issues within the evaluation engine if we tried to represent a row with hundreds of thousands of email addresses.
The most serious problem though is that we lack the ability to manipulate this nested structure in a first-class way. Effectively, all query machinery in all contexts is heavily row-biased. Think about it. If you do a SELECT COUNT(*) FROM weather you’ll get a count… of the rows. If you want to find the average temperature you can can so long as each temperature is on a separate row. There is no meaningful way of applying this machinery to structure within a row.
This is why MRA adds a first-class notion of dimensionality. So in the above dataset, the row axis is one dimension, the fields within the rows are a second dimension, and the structure within the rows is a third dimension. So now we have a dimension for each person, a dimension for their first-order attributes, and a dimension for their emails. MRA allows us to go even further and continue adding dimensions for each level of nested structure, without any limit!
Major-Axis Rotations
Of course, none of this dimensional hocus-pocus actually means anything unless we can leverage it to solve the problem of accessing and manipulating this nested structure. This is where MRA starts to truly shine. MRA defines a pair of operations, inflate and reduce, which allow expressions to manipulate the dimensionality of an underlying dataset. In particular, the inflate operator makes it possible to pull out the highest-order dimension from within a row and project it into the row dimension. This operator forms an isomporphism when taken together with the reduce operation, which strips off a projected dimension from the row axis and composes it back into “value space”, pushing the data back into individual rows.
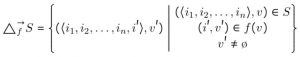
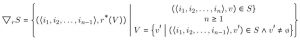
As a significant aside, the name “reduce” and its similarity to the general name for operations like COUNT, AVERAGE, SUM and such is not a coincidence. As it turns out, these operations are dimensional even within the context of conventional RDBMS systems! For example, SELECT SUM(*) FROM numbers takes the projected row (consisting of a single projected dimension: the identities of the rows) and strips it off, collapsing everything down to a single value which has no dimensional information: the sum of all the rows. This observation allows MRA to generalize conventional reductions to operate over projected structural dimensions.
For example, let’s imagine that we have a JSON dataset where each row contains a nums field, which itself is an array consisting of some set of numbers. Something like this:
{ “nums”: [1,2] }
{ “nums”: [3,4,5] }
{ “nums”: [6] }
If we wish to obtain the average value of the numbers within each row, we can do this by inflating dimension represented by the nums array into row space, then applying the AVERAGE reduction to strip the projected dimensionality and fold the results back into value space. Expressed in a SQL-like syntax:
SELECT AVERAGE(INFLATE(nums)) FROM data
MRA says that the result of the INFLATE operation is a dataset which as two projected dimensions: the identity of the rows, and the identity of the array indexes. As with any reduction, the AVERAGE operation strips off a single projected dimension and folds the results back into value space, meaning that the results of the AVERAGE reduction will be a set of values (not just one value!), each of which is the average of the numbers within its respective row:
1.5
4
6
All of this gets a little heady and has some extremely complex implications, but the symmetry of the mathematics allows for some very powerful properties to emerge. More importantly, it gives us a meaningful way to talk about structure within a row with the same easy that we talk about the rows themselves. This is incredibly powerful, and it means that structure and nesting are suddenly irrelevant concerns: it’s all isomorphic to well-defined row projections via inflate!
It also means that we have a uniform and deterministic method for converting any nested structure into something that is flat and tabular, enabling the use of tools which work best in the two dimensions of columns and rows ? such as Tableau, Excel, Power BI, and R ? to be brought to bear. In a very real sense, this pair of operations forms the core of Precog and everything we do at Precog.
Correlation, Surrounding Structure, and AUTO JOIN
An extremely common use of nested structure (particularly arrays) in operational datasets is to indicate a large set of items which all share a common set of information, represented by the fields outside the nested structure. As a simple, contrived example:
{ “country”: “USA”, “state”: “Colorado”, “postcodes”: [80301, 80302, 80303, 80304] }
{ “country”: “USA”, “state”: “Wisconsin”, “postcodes”: [53090, 53091, 53092] }
When examining this data and attempting to flatten it, we can’t just consider the nested structure within postcodes. If we were to do so, we would entirely miss out on the critical information which is available in the top-level fields, country and state. This begins to hint at something really important: inflate must take non-inflated dimensions into consideration when projecting the nested dimension into row space. In other words, we do not want the inflation of this row to be the following:
80301
80302
80303
80304
53090
53091
53092
These are just… numbers. They’re devoid of the correlated information from the top level object. Instead, what we really want is the following:
{ “country”: “USA”, “state”: “Colorado”, “postcode”: 80301 }
{ “country”: “USA”, “state”: “Colorado”, “postcode”: 80302 }
{ “country”: “USA”, “state”: “Colorado”, “postcode”: 80303 }
{ “country”: “USA”, “state”: “Colorado”, “postcode”: 80304 }
{ “country”: “USA”, “state”: “Colorado”, “postcode”: 80305 }
{ “country”: “USA”, “state”: “Wisconsin”, “postcode”: 53090 }
{ “country”: “USA”, “state”: “Wisconsin”, “postcode”: 53091 }
{ “country”: “USA”, “state”: “Wisconsin”, “postcode”: 53092 }
The top level information needs to be replicated for each row in the output, which in turn is determined by each member of the array. This semantic is extremely intuitive, and as it turns out, formally falls out of one of the core operators needed to make MRA hold together in the first place! We call that operator the auto join.
Auto join really just formalizes the intuition that “data which came from the same place via two different transformations should retain its correlation when put back together again”. As a quick example, take the following dataset:
{ “a”: 1, “b”: 10 }
{ “a”: 2, “b”: 20 }
{ “a”: 3, “b”: 30 }
If we were to evaluate the map the expression a + b over this dataset, you would expect the results would be the following:
11
22
33
This is highly intuitive. The a and b values are kept paired. However, if you actually look closely at the expression a + b, this seems like it might be a bit problematic. In particular, we would imagine that the sub-expression a, when evaluated on its own, would produce the following dataset:
1
2
3
Similarly, evaluating the sub-expression b would produce the first three multiples of 10. This raises a problem though: if both these sub-expressions produce these datasets respectively, then what exactly is the meaning of the binary operation, +, when applied to both of them? In more mathematical notation, we’re literally asking the meaning of the following notation:
{1, 2, 3} + {10, 20, 30}
But… you can’t add sets! That doesn’t really make any sense. We need to define a way to lift the + operation such that it can be applied to these two datasets. Unfortunately, the most mathematically obvious way to do this also turns out to be completely useless: the cartesian. No one really wants the following to result from a + b:
11
12
13
21
22
23
31
32
33
It’s nonsense! And it’s also explosively slow and impractical, because it doesn’t take very much data to produce cartesians which represent more data than can be represented by all the molecules on the planet.
Instead, we want to find a way to correlate the rows in the dataset resulting from a back with the rows from the original dataset, and equivalently for b, so that the + operation can be mapped over the pairs which originate from the same row, discarding all the others.
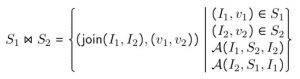
This operation is formalized by the auto join in MRA, and it turns out to be extremely vital for solving the postcodes problem from earlier. If you recall the description of the inflate operator, when it flattens the nested postcodes array into row space, projecting the array dimension into the row dimension, it retains the identities of the rows! This is done so that operations like SELECT AVERAGE(INFLATE(nums)) can produce one value per row, where the value is the average of the numbers within the nums array. Retaining row identities is critical here, and it interacts in a very pleasing way with auto join.
Just as we want the values of a and b in the expression a + b to pair up according to their original rows, so too do we want the values of country and state to pair up with the inflated values of postcodes according to their original rows. As it turns out, this falls out directly from the mathematical description of auto join, and we don’t even need to do any extra work for it! The auto join says that things correlate back by their origin identity, which in this case means the row, and so all we need to do is auto join the inflated postcodes back to the original structure (country and state), and we get exactly the result we want!
Critically, these properties directly fall out of a simple and orthogonal set of mathematical equations (described in terms of basic set theory). This is such an important property because it means that we don’t have to think carefully in advance about how to handle weird and complicated corner cases of datasets. We already know that we can handle all of them, because we can prove it formally, and we know that we handle all of them with the same consistent semantics with which we handle these simple examples. MRA scales to truly arbitrary levels of nesting, with exactly the same semantics and meaning.
Dealing with Heterogeneity
There’s one last little detail that is required from any system which wants to deal with data that is “messy” by any definition: a sane way of dealing with heterogeneity. To be clear about what I mean, the following dataset is heterogeneous:
{ “type”: “ERROR”, “severity”: 3, “value”: “the system is down, yo”, “time”: 1549580383184 }
{ “type”: “INFO”, “value”: “checkin’ the email”, “time”: “2019-02-07T23:00:13+0000” }
This dataset is heterogeneous in two ways. First, the severity field is present in the first row, but not in the second. Given that this seems to be log data, we can probably guess that severity is only meaningful for ERROR type entries, but obviously that would only be a guess. The second form of heterogeneity is probably the most common one in the whole industry: storing times as milliseconds since UNIX epoch, versus storing them as ISO datetime strings.
Both of these instances of heterogeneity are things that need to be normalized away before the data can be ingested into any sort of static-schema system (such as an RDBMS, or really any data warehouse), where every row must comply precisely with a pre-selected set of column names and types. Additionally, the evaluation model itself must be capable of dealing with the unexpected discovery of these sorts of things while still producing meaningful results, and that is where a surprisingly simple and yet extremely powerful feature of MRA comes into play: undefined filtering.
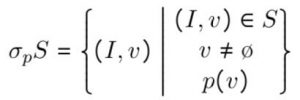
Whenever a value is selected which does not match the type and structural constraints of an operation, MRA semantics say to simply drop that value on the floor! As an example, if we were to select the severity field from the above example dataset, the results would be just the following:
3
There would be no error. No exceptional case or default value to fill in. The value just… goes away. As it turns out, when we combine this with auto join semantics, we get an extremely uniform way of handling erroneous cases! Specifically, the absence of a value remains correlated with its original row in the same way that the presence of a value would be, meaning that we have the ability to reconstruct row state around an absent or unexpected value, producing meaningful results even when the schema has shifted.
This is best seen in the solution to the datetime format mismatch issue. Internally, Precog defines an operator we refer to as ??. This is a binary operator which has auto join semantics, just as with every other operator in the meta-model. This operator produces results for each row by looking at the left hand side and inspecting whether the value is absent. If absent, it uses the right hand side. Really, it’s just a simple default value operator, but lifted via auto join to apply across an entire dataset at once. This allows us to provide separate conversions for the same datetime field in our original dataset, merging them back together again using ??. In pseudo-SQL syntax:
SELECT type, value, FROM_EPOCH_MILLIS(time) ?? FROM_ISO_STRING(time), severity ?? 0 FROM logs
And this works! We’re able to elegantly normalize the time column, without having to worry about error cases or fallbacks, simply because MRA handles value non-existence (or equivalently, value invalidity) with the same semantics that it applies to value existence.
Summary
Taken all together, MRA is an incredibly powerful model for dealing with heterogeneous structured data. Which is, not coincidentally, exactly the sort of data that you’ll find in mind-bending volume in pretty much every data lake ever. Despite its extreme power, MRA remains simple and orthogonal enough that it can be formally described in terms of set theory in just three pages (most of which is whitespace caused by LaTeX’s formatting constraints). This simple and straightforward model forms the foundation of Precog, giving us a provably consistent and uniform method for answering any question about any dataset.








