
Something is happening out there. The world is changing, ever so slowly, but it’s changing. The temperature in the pot has been rising for the past few years now, and we, the frogs, are only now starting to notice. It’s a convergence of events that, while early overlooked, will cost you dearly if you don’t take notice.
A couple of years ago, Forbes began to notice a trend, commenting that “customer/social analysis is considered the second most important big data analytics use case…” With the rise and now dominance of social platforms like Facebook, Twitter, TikTok, LinkedIn, and others, it’s not hard to see why social analytics has become a critical part of any company’s data plans.
Not long after, we heard that “90% of IT professionals plan to increase spending on BI tools,” again from Forbes. That’s odd. Isn’t the market already saturated with analytics tools and platforms? Doesn’t everyone already have what they need? For the answer, we need to consider another finding: “40% of businesses say they need to manage unstructured data on a frequent basis.” (Forbes) And that’s the key — unstructured or semi-structured data.
In just a few short years, we’ve shifted from a world dominated by forms and structure to one of tweets, posts, likes, and shares. It’s a new world, and the rules of data and analytics need to change as well. What’s changed, and what do you need to know and do to take advantage of this new reality? Here are the new rules for this new world.
New Problems Abound
As we’ve become better at dealing with data that comes from traditional, structured data sources, the world has changed around us. Instead of simple columns and rows, today, we find ourselves challenged more and more to use video, JSON files, and other semi-structured data generated by a host of platforms that simply didn’t exist at the dawn of the data age.
And, these data sources are increasingly API-based. That means that tools that were using old-fashioned file transfers to get data from the source have to be retooled to make use of API-based data. Designed in an age when data was transferred in bulk via nightly loads, vendors of analytics platforms are faced with a dilemma: either perform expensive development projects to add connectors for all possible data sources or but them one by one from a vendor, or… simply leave it to the buyer to solve the problem. It’s a lose-lose situation.
In the need to connect to many data sources, vendors have seen a huge business opportunity and they’ve capitalized in a massive way. Some companies have built an entire business on the creation and selling of connectors to every data source imaginable. Need a Salesforce connector? Got one — that will be $1200/month please. A bit more depending on how much you use it… If you need to connect to multiple data sources, it adds up fast. You can easily find yourself managing — and paying for — a jungle of connectors to your data.
These new sources of data wouldn’t be much of a problem if we could unlock them using the tools of the past — throwing people at the problem — but this is difficult in today’s environment. Since unstructured data (and the need for data in general) is now the norm and not an edge-case, the demand for data engineers to find, extract, transform, load, manage, and maintain data has exploded. In fact, a recent survey found that “data engineer” was the fastest-growing, most in-demand jobs in technology in 2019, growing by 50% year over year. Finding those resources to turn semi-structured data into useful analytics is going to be tough — paying for them is going to be impossible for all but the most budget-rich businesses.
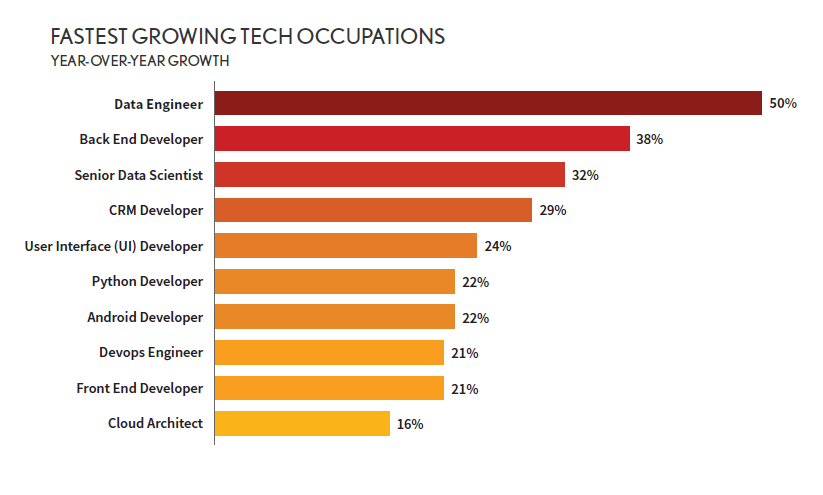
It gets worse. Combined with new data structures that are more difficult to unlock and the skyrocketing demand for the data engineers who can get to this data, business agility is more critical than ever. Just ten years ago, it wasn’t uncommon to find big businesses that operated like this:
- Identify a business/technology problem
- Hire a big consulting firm
- Spend a month having the consultants scope the problem
- Spend a few weeks on the budget allocation and RFP process to find the right vendor
- Take the next 6-9 months (if you’re lucky) implementing the solution to that problem you found nearly a year ago.

Can you imagine operating at this turtle-grade pace today? You’d be out of business before you had the purchase order signed. Modern data-dependent companies can’t afford to wait. They need to respond to their customer, to their competitors, and to market conditions quickly and effectively. That’s difficult when you’ve got data locked away, and the people who can access that data are both hard to find and extremely expensive. Agility becomes a faded dream.
Old Technology Fails for the New Challenges
Technology comes to the rescue! Or does it? Traditionally, for nearly every problem we’ve experienced in the business world, there’s been an easy solution at hand. Need to be able to manage marketing campaigns at a massive scale? No worries — you’re covered. Need to be able to track every sales opportunity and project which deals will close? There’s tech for that.
Analytics is different. Most analytics platforms were designed in a different age, where data was loaded in batches and was almost certainly highly structured. Unsurprisingly, this is the environment to which most analytic platform vendors developed. They added powerful ingestion capabilities that could load massive data sets quickly. They created flexible ETL tools to combine, cleanse, and prepare the data. They built entire ecosystems that would help businesses turn their data into value.
But the world changed, and analytics users are now facing a struggle.\
The New Rules

Just as they’re facing the need to operate with agility, to wrangle data without expensive experts, and deal with unstructured or semi-structured data like video, the technology has let users down. These users are faced with significant challenges just when they can least afford them.
Semi-Structured? We’re Out.
Let’s be blunt: most analytic platforms simply can’t easily deal with modern, semi-structured data. It’s a bit of a secret in the industry, but most vendors will be forced to admit the shortcoming when pressed. Here’s how that conversation usually goes:
| You: | Can you bring in semi-structured data? |
| Vendor: | Sure, we can! We do it all the time. |
| You: | So, if I’ve got — let’s say — a 50MB JSON object that changes from load to load, and you’ll need to traverse that object and make sure that no fields have been modified or added, you can do that? |
| Vendor: | Um… Well, our services team is really good… Plus, um, we’ve got some connectors… |
They don’t have the native capability to deal with what you find in the real world — vast, partially structured data sets that change on occasion. It’s not their fault — the world looked different when they were designing their system. Which leads to the next challenge:
Python Isn’t a Snake; It’s a Bear
The way vendors deal with the new data world is through code, typically Python or Java among others. Or rather, they make YOU deal with their deficiencies by hiring people to write the code. Has the data changed? Write some more code. Did the code catch ALL the changes? Hmmm. Write some code-checking code. It’s a lot of code to create each time anything in your business data changes. Oh, you’ll need to maintain all that code as well. All of which leads to yet another issue:
The Magical World of Unlimited Time and Budget
Who’s going to be writing all of that code to handle the large, complex, nested, and ever-changing data that is common today? That’s right: consultants. Typically, companies are forced to hire consultants or contractors each time a change is required. It’s time-consuming, taking weeks or longer to make each change, and it’s expensive, as we noted earlier. Alternatively, you could hire a full-time, dedicated “write us some Python every time the data changes” person, but that wouldn’t be very efficient either.
It’s a bit of a dilemma: more need for data, the data is unstructured, resources are expensive, and the tools of today just aren’t designed to handle the problem. You’re stuck.
Precog: Built for the New Rules of data

Precog does one thing and one thing only: we make unstructured or semi-structured data ready for analytics. When faced with all of the problems we discussed above, the team at Precog decided that enough was enough. We didn’t want to see companies hiring expensive consultants every time they needed new data. We weren’t satisfied with the so-called “connectors” that are custom made for each and every data source and structure. And we absolutely weren’t going be deluded into thinking that we’d eventually revert to the old, structured world. So we built a solution.
The Precog Intelligent Data Load is built for today. API-first, AI-powered interpretation of semi-structured data, easy to use, and fully-embeddable for a seamless experience in any application or data platform.
Our API-first approach means that any system that produces data accessible via an API can be easily connected with Precog. And that means just about any modern system on the market, from Alteryx to Avalanche, from Tableau to Tensorflow — we can get the data out and ready to use in minutes, with zero coding.
JSON and CSV (semi-structured data) is our bread-and-butter.
But it gets better. Instead of selling you a new connector each time you discover a new data source, Precog is your “Universal API Connector” unlocking any data source imaginable with a single, easily managed, quickly deployed, and cost-effective connection. In fact, we’re as proud of our ability to eliminate the need for hundreds of connectors and all the work required to mange it all as we are of our AI-powered data loading innovations. The days of wrangling connectors along with all of your data are over.
We use our innovative engine technology to turn massive, complex data JSON data into tables that any analytic tool can use. And we do it all in a few steps that anyone, not just a data engineer, can perform. Anyone.
For analytic vendors that want to add unstructured data power into their solutions without rewriting their entire code base, Precog is fully embeddable and can be white-labeled. Imagine that conversation with a customer and being able to answer “yes, we can handle that 50MB JSON object that changes from load to load.” With Precog, you can say to any data source, unstructured, semi-structured, or even structured, without the headaches.
The new world of data has new rules that might seem scary at first, but it doesn’t have to be that way. The trick is to use a tool — like Precog — explicitly designed for the world where data is messy, experts are expensive, and agility is vital.
At Precog, we live and work in this world every day, and we’d like to show you around. It’s pretty great out here








