
Tabulating non-tabular data with Precog
With Precog, we connect directly to the source of the data. In this case the source is the FDA.gov Web API. This ensures that we are always working with the latest data including new records and corrections. There is no need to download, stage or import the data. Self service users can add their own sources and commonly used sources can be added in advance so that self-service users don’t need to do this themselves.
Like many web data sources, FDA.gov provides data in a paginated manner. This means that the dataset is not available as a single document, rather it is made up of multiple documents. Precog handles this pagination for us.
We’ll use the following datasets in our analysis:
Adverse events relating to NSAID drugs indicated for Osteoarthritis:
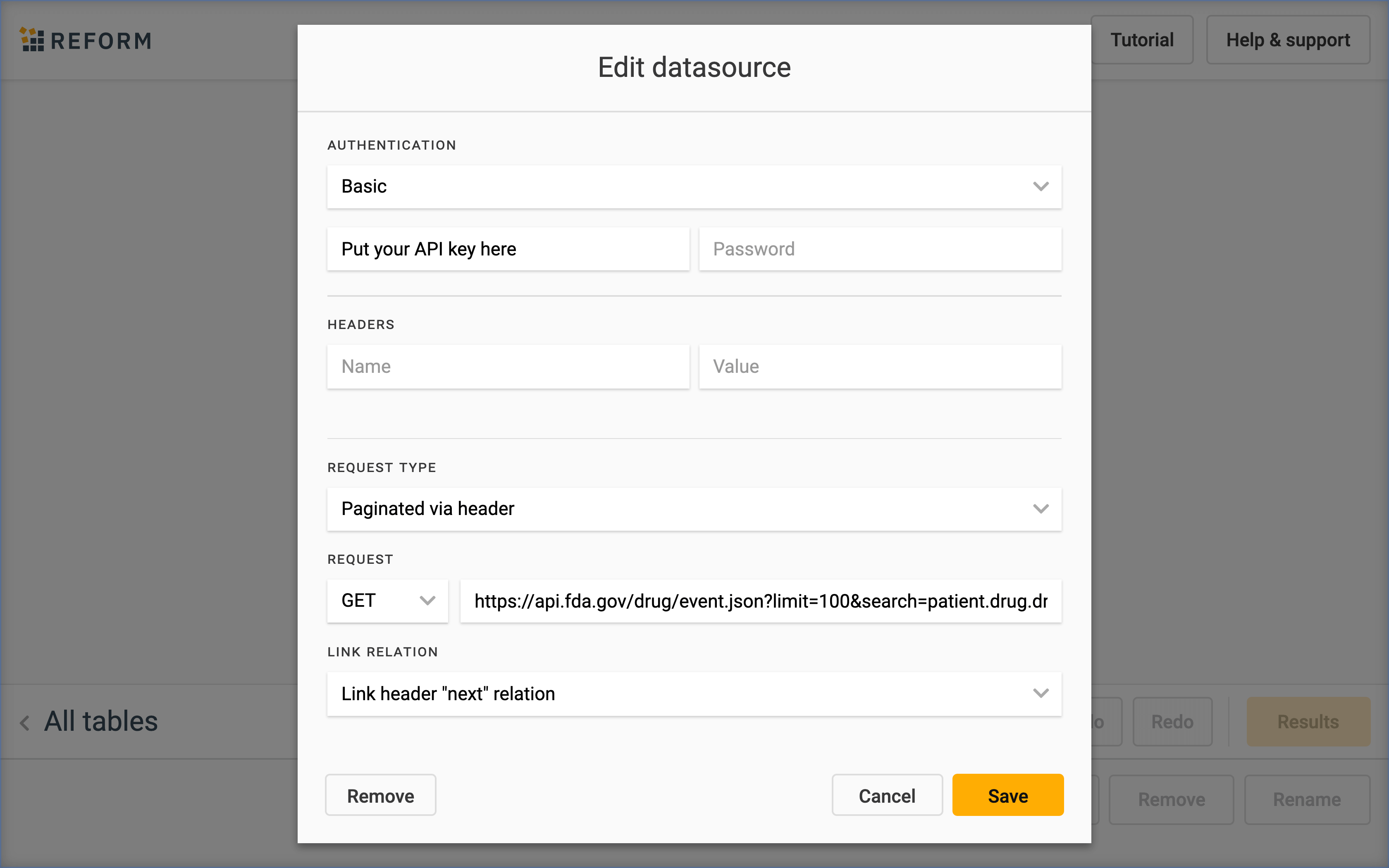
https://api.fda.gov/drug/event.json?limit=100&search=patient.drug.drugindication.exact:OSTEOARTHRITISIn order to retrieve all the pages we’ll need to get an API key from FDA.gov, provide this as a basic authentication username and select Paginated via header as the request type. Precog also supports offset and token based pagination.
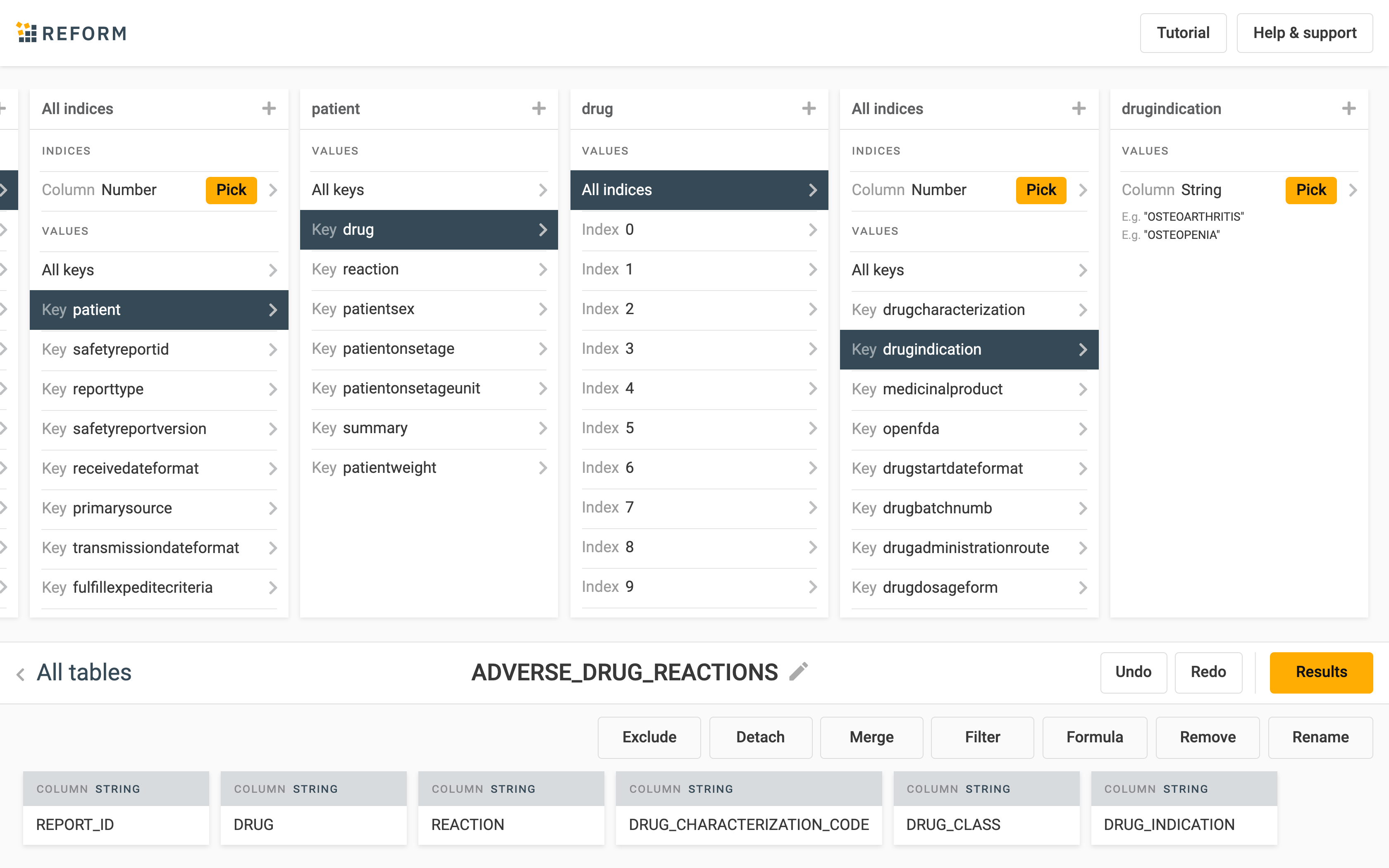
Precog instantly shows us the available data and allows us to browse it. To tabulate the data we simply pick what we are interested in and it appears as columns in the table below. Here we are interested in the id of the reports, as well as reactions and information about drugs.
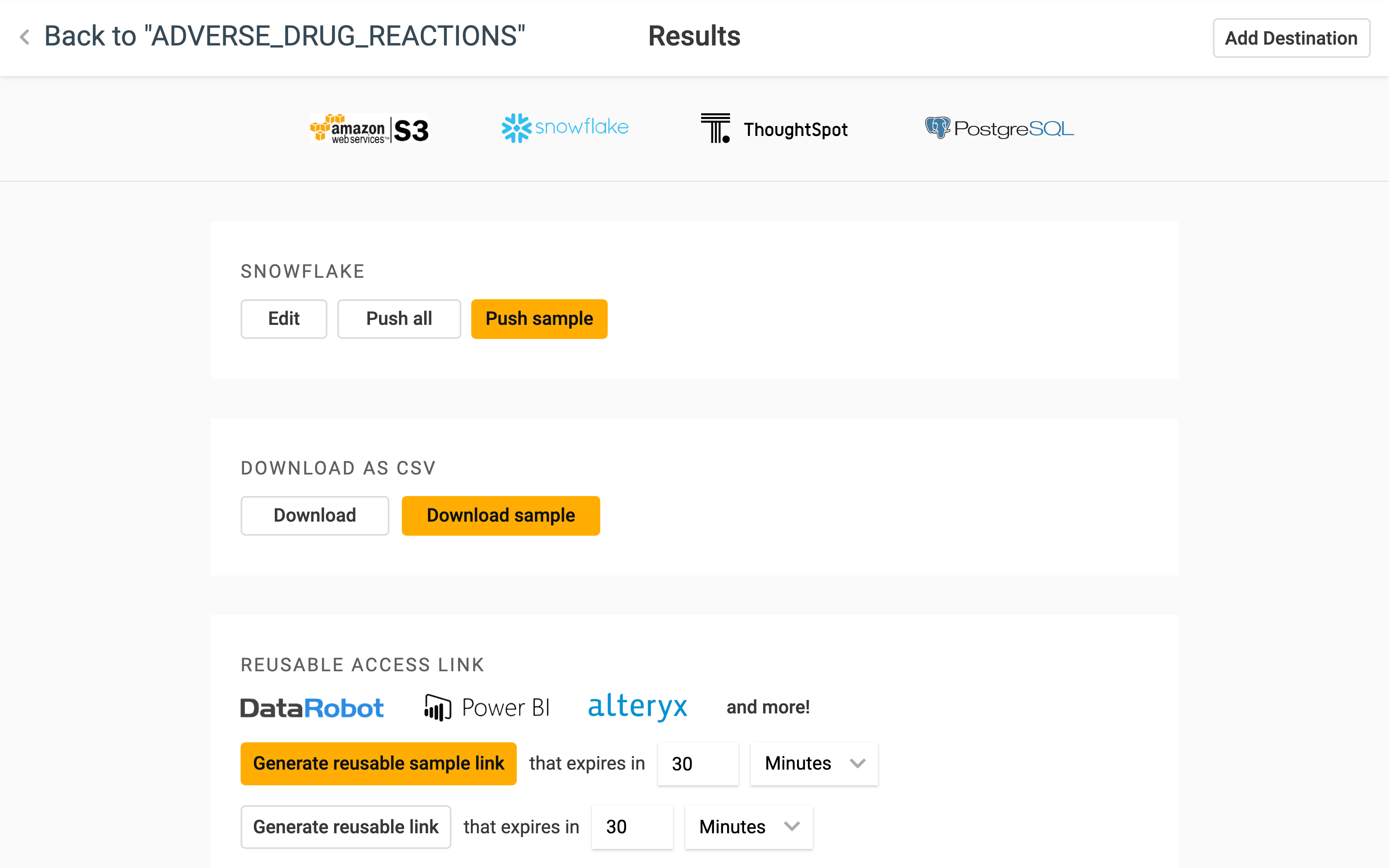
Now that we’ve picked out our table we can analyse the data directly, using software such as Power BI, DataRobot, Alteryx and ThoughtSpot, or push it into warehouses and databases such as Snowflake and Postgres. Every time we access the results Precog provides the latest data from the source.
We can think of using Precog like online shopping, except instead of a cart we have a table. We can browse, pick what we want and then check out. Now that we’ve “checked out” we can use software such as Power BI, ThoughtSpot, Looker, Tableau or SQL to analyse and manipulate the data.
To summarize, we have:
- Added the FDA Web API as a data source, letting Precog automatically deal with the paginated data
- Browsed the available data fields from the non-tabular data
- Picked the data were are interested in, letting Precog automatically tabulate the data for us
- Loaded the tabulated data into Snowflake or Power BI
By doing this we have now successfully paged, downloaded, imported, explored and tabulated the non-tabular data.








