

The Precog solution enables data analysts and engineers to access complex JSON data as tables. In many cases we want those tables to be stored in Microsoft SQL Server or some other SQL database engine. Such requirement can be implemented easily using Precog and Azure Data Factory.
Transforming JSON to tables in Precog
Let’s say we want to store data about SpaceX’s rocket part reuse for later analysis in a SQL Server table. We can get this information from a public API (https://api.spacexdata.com/v3/launches). This API, as many others, returns requested data as JSON.
Precog allows us to directly process JSONs available via a public URL. We can easily transform the complicated structure provided by SpaceX API into a simple table. For our use case we need just 5 columns: date of launch, name of part, and boolean flags telling us whether the rocket (center core), side cores or payload (Dragon spacecraft) were reused. We end up with a following virtual table:
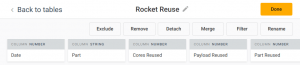
In addition to public URLs you can also process JSON files stored in Amazon S3, Azure Blob Storage, Wasabi or MongoDB. Once the virtual table is defined, we can access the live results as CSV using a sharing URL provided by Precog. 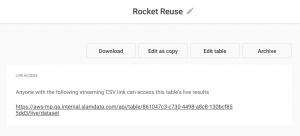
Ingesting data using Azure Data Factory
Azure Data Factory is a data integration tool developed by Microsoft. Besides many other great features, it provides a user-friendly way of moving data between multiple data sources. Although it is a part of Microsoft’s Azure cloud, it is not limited to services hosted on the platform. You can use it easily with your on-premise services as well.
In this case we want to store the data in Microsoft SQL Server. But Azure Data Factory is not limited to this service. It also provides connectors for MySQL, PostgreSQL and many other popular solutions.
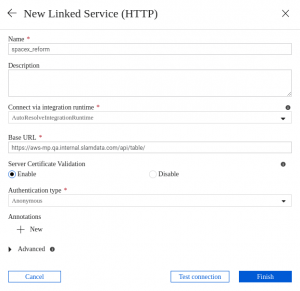
You can access Data Factory from Azure Portal. Data Factory allows you to choose an HTTP service as a data source. This perfectly suits our needs since our table is available as a URL.


When adding a HTTP service we recommend providing just the static part of the table address as the Base URL value.
The rest of the table URL should be entered in the Relative Url field in the next step of the Copy Data wizard:
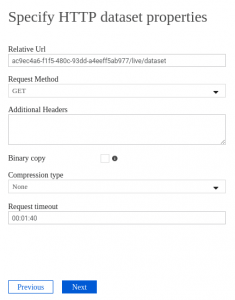
Data Factory asks you to specify the file format. Precog uses CSV (Text format) with comma (,) as column delimiter. First line of the file contains column names. 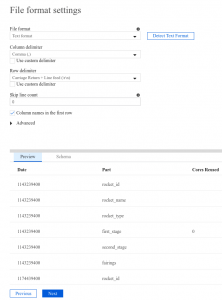
We should also specify the columns data types, since standard CSV format does not provide a way to store this information.
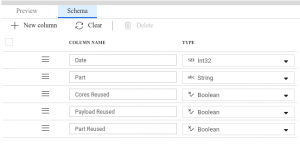
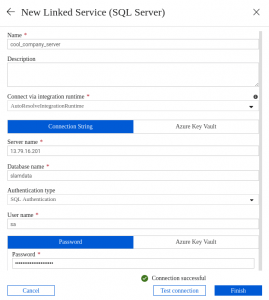
After we defined our source data source, we can move to destination. As mentioned, in our case we select the SQL server option and simply provide all the information required to open a connection.
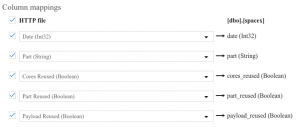
Next, we select the target table and define how the CSV columns are mapped to the database table. For each database column we simple select the corresponding CSV column from the list.
After both source and destination are defined we can deploy the pipeline.
After the process finishes, we can verify that the data is indeed stored in our database as a table, for example with Azure Data Studio:
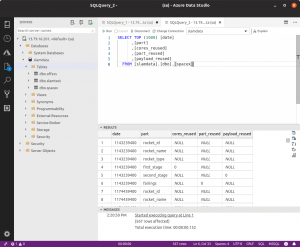
The data is now ready to be used in any SQL Server compatible application.
In this short post we have shown you just one use of Precog – ingesting data from a JSON API into a SQL Server table. To keep things short we skipped some parts of the process such as virtual table definition in Precog. Check the full User Guide if you are interested in details or have never used Precog or Microsoft Azure before.
Storing JSON data as tables in SQL Server is just one use case of Precog. The possibilities provided by the tool are much wider. Precog can process data from MongoDB, files stored in S3 or Azure Blob Storage or any public URL providing JSON data. Created tables can then be easily analyzed with well known tools such as Power BI or Tableau. Adding Data Factory to the mix, we can stream the output to many destination types including SQL Server, Azure Data Warehouse, MySQL or PostgreSQL.
If you want to know more about Precog, please contact us [email protected]








