
Blog
Our latest Blogs & News

Precog Achieves Google Cloud Ready – BigQuery Designation
Today we’re excited to announce that we have successfully achieved Google Cloud Ready – BigQuery Designation.

Top 4 ELT tools for SAP 2024
The following is an analysis of the top four vendors offering data integration (ETL/ELT) solutions in the SAP ecosystem.

Turbocharge your ServiceTitan Analytics and Reporting
Precog is a simple to set up AI powered solution that lets any user get all their ServiceTitan data via the API and make it available as fully business ready data for doing advanced analytics, machine learning, and combining with other data sources.

Precog for the Enterprise – SAP Ariba ELT
Precog is the only Al-powered ELT tool allowing enterprise class customers to move the millions of rows required out of SAP Ariba and 2,000+ other sources today into the market’s leading data warehousing solutions.

How Precog’s AI-Powered, Multi-Source Analytics Helped American Landscape Partners Scale
This case study explores how American Landscape Partners leveraged Precog to radically simplify loading data into Snowflake from Acumatica, Paylocity, and Aspire.

Precog’s AI-Powered ELT platform makes loading data into SAP DataSphere simple and fast
Precog has completed the rigorous SAP integration testing and is now a certified SAP integration partner. SAP’s 425,000+ customers now have access to Precog’s 2000+ AI-powered connectors — including the ability to add new API data sources in a day.
Precog delivers AI-Driven ELT to Snowflake ecosystem as certified partner
Precog has completed the rigorous Snowflake integration testing and is now a certified Snowflake integration partner. Snowflake’s 8500+ customers now have access to Precog’s 2000+ AI-powered connectors — including the ability to add new API data sources in a day.

What is AI for data integration? And why does it matter?
Since our founding in early 2020, Precog has had a single vision: using AI and ML to solve the problem of creating ELT connectors to any and every API. We have realized this vision entirely, and the market is taking note. The following blog describes how we did it.

How A Luxury Gelato Chain Uses Precog to Actually Get Realtime, Multi-Source Analytics
This case study explores how Snowflake Gelato leveraged Precog to radically simplify loading data into Snowflake from Cin7 Core, MarketMan, Xero, and Workforce.

SAP Insider Says Precog Delivers Analytics-Ready Data From Everywhere
Precog is uniquely positioned to help all SAP organizations. Precog’s platform integrates seamlessly with SAP’s sources and destinations to ensure that users can maximize the value of their data.

New partner: StarPoint Technologies
Precog Data, Inc., announced a new strategic partnership with StarPoint Technologies, Inc., a leading provider of enterprise data and business intelligence services and solutions.
Turbocharge SAP analytics through no-code data integration
SAP’s enterprise software is used by 80% of the world’s Fortune 500 companies and 98% of the world’s most valuable brands. Whether a company is using SAP’s ERP, supply chain, spend management or human resource solutions, your data is useless if you can’t analyze it.

Shopify Data to Snowflake, BigQuery, Postgres, SQL Server…
Welcome to Precog Express. Precog Express is a universal data connector. It lets you pull data from any source and send it just about anywhere ⎼ streamlining the entire data integration process. Let’s take a look around.

ServiceTitan Data to Snowflake, BigQuery, Postgres, SQL Server…
Welcome to Precog Express. Precog Express is a universal data connector. It lets you pull data from any source and send it just about anywhere ⎼ streamlining the entire data integration process. Let’s take a look around.

Leaflogix Data to Snowflake, BigQuery, Postgres, SQL Server…
Welcome to Precog Express. Precog Express is a universal data connector. It lets you pull data from any source and send it just about anywhere ⎼ streamlining the entire data integration process. Let’s take a look around.

Google Adsense Data to Snowflake, BigQuery, Postgres, SQL Server…
Welcome to Precog Express. Precog Express is a universal data connector. It lets you pull data from any source and send it just about anywhere ⎼ streamlining the entire data integration process. Let’s take a look around.

Google Ads Data to Snowflake, BigQuery, Postgres, SQL Server…
Welcome to Precog Express. Precog Express is a universal data connector. It lets you pull data from any source and send it just about anywhere ⎼ streamlining the entire data integration process. Let’s take a look around.

Applovin Data to Snowflake, BigQuery, Postgres, SQL Server…
Welcome to Precog Express. Precog Express is a universal data connector. It lets you pull data from any source and send it just about anywhere ⎼ streamlining the entire data integration process. Let’s take a look around.

Apple Store Connect Data to Snowflake, BigQuery, Postgres, SQL Server…
Welcome to Precog Express. Precog Express is a universal data connector. It lets you pull data from any source and send it just about anywhere ⎼ streamlining the entire data integration process. Let’s take a look around.

Apple Search Ads Data to Snowflake, BigQuery, Postgres, SQL Server…
Welcome to Precog Express. Precog Express is a universal data connector. It lets you pull data from any source and send it just about anywhere ⎼ streamlining the entire data integration process. Let’s take a look around.

Admob Data to Snowflake, BigQuery, Postgres, SQL Server…
Welcome to Precog Express. Precog Express is a universal data connector. It lets you pull data from any source and send it just about anywhere ⎼ streamlining the entire data integration process. Let’s take a look around.

Amazon Selling Partner Data to Snowflake, BigQuery, Postgres, SQL Server…
Welcome to Precog Express. Precog Express is a universal data connector. It lets you pull data from any source and send it just about anywhere ⎼ streamlining the entire data integration process. Let’s take a look around.

SAP Data Integration Using Precog: SAP Ariba to SAP Data Warehouse Cloud to SAP Analytics Cloud
Welcome to Precog Express. Precog Express is a universal data connector. It lets you pull data from any source and send it just about anywhere ⎼ streamlining the entire data integration process. Let’s take a look around.
Introduction to Precog Express
Welcome to Precog Express. Precog Express is a universal data connector. It lets you pull data from any source and send it just about anywhere ⎼ streamlining the entire data integration process. Let’s take a look around.

New sources: Oracle Hospitality Opera, Infor SunSystems, Serverstack, Hologram, Verizon Thingspace, and many more
Precog continually adds new sources. This week’s roundup includes: Ardunio, Ardunio PubSubClient, FronteggGUS, GermanyHCSS, HiveMQ, Hologram, Infobip, Infor SunSystems, Microsoft Service Bus, Mosquitto, Oracle Hospitality Opera, Paho, Paho Android Service, Paho Eclipse, Qualtrics XM, Serverstack, ServiceTitan, Shop Aware, SkysoftConnections, Swift, Trimble Viewpoint, Verizon Thingspace, Wolf MQTT / Wolf SSL, Wolf SSL.

New sources: Commission Junction, Corner Stone on Demand, Crypto Compare, and more
Precog continually adds new sources. This week’s roundup includes: Commission Junction, Cornerstoneondemand, Crypto Compare, EOD, Great Plains MFG, Great Plains AG, Google NLP, Google Vision, Hijump, Nomics, OUI, Service Monster, SEC Edgar, SEC Filings, Skip Tracing, Twilio, Teads, TimeToReply, Parcel2go, and Xedi.

New sources: Ava Security, Oracle Hyperion, Alibaba, Redox, and more
Precog continually adds new sources. This week’s roundup includes: Ava Security, Ava Aware Cloud, Openpath Security Inc., Housecall Pro, Thumbtack, Shoppe, Flipkart, Tank Net, Oracle Hyperion, Hyperion, SEMA Data , OptiCat, LLC, Alibaba Group, Legal Metrics, Tracker Legal, and Redox.

The Failed Promise of Cloud ETL
With the constant explosion of new data sources and applications, both public and private, the old way doesn’t scale, period. What does scale is Precog’s concept of “just-in-time data sources.”

New sources: Photon Commerce, Flowxo, Zenefits and more
Precog continually adds new sources. This week’s roundup includes: Photon Commerce, Flowxo, Staffbase, Evalanche, Leapsome, Matomo, DMSI, Investorfuse, ECI Solutions, ECI Spruce, and Zenefits.

Access the Top Marketing Analytics Sources, Including APIs
Precog allows you to access live, ready-to-query data from any source — that includes the top Marketing data sources and APIs.
Access the Top Productivity Data Sources, Including APIs
Precog allows you to access live, ready-to-query data from any source — that includes the top...

Access the Top ERP Data Sources, Including APIs
Precog allows you to access live, ready-to-query data from any source — that includes the top ERP...

Access the Top Payments Data Sources, Including APIs
Precog allows you to access live, ready-to-query data from any source — that includes the top...

Access the Top Advertising Data Sources, Including APIs
Precog allows you to access live, ready-to-query data from any source — that includes the top advertising data sources and APIs.
Everflow Chooses Precog To Power Its Advanced Marketing Analytics Service
Everflow, a performance marketing analytics company based in Mountain View, CA, has selected Precog to help power its data integration service that powers its performance marketing solution.
SAP Ariba Reseller SouthEnd Partners With Precog To Grow Analytics Services In Latin America
SouthEnd, an SAP Ariba reseller focused on Latin America, chose Precog, a data integration provider based in Boulder, CO, to power growth in its Ariba-based analytics business.
Precog Opens New Era of Analytics By Providing over 6,000 Analytic ready Connectors for Power BI, Tableau, Qlik, Looker
Precog has surpassed 6,000 data source connectors supporting any BI or Data Warehouse solution.

Why You Are Confused About Data Integration
Be confused about Data Integration no longer! Read ahead to know how to use Precog to integrate any data source or destination.

How To Access Any Data Source from Alteryx
A quick video and transcript from Alteryx Inspire — how to access any data right from Alteryx.

API “palooza” — Connecting Any API To Alteryx In Minutes
Join Precog at Alteryx Inspire 2021 to learn how to unleash the power of Alteryx on thousands of Web APIs with simple, super-fast workflows.
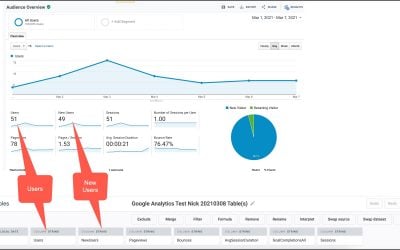
Google Analytics Cross-Property Roll-Up Reporting (Or How To Aggregate Data From Multiple Websites Into One Always-Up-to-Date Report)
Learn how to create consolidated Google Analytics report without custom development.

New: Precog Partners With Wasabi To Make Hot Cloud Storage Analytics-Ready
We’re excited to announce a new partnership with Wasabi, the cloud storage company that is 80% less expensive and faster than S3 (and no fees for egress or API requests!). Precog makes it radically simple for non-technical users explore and work with data in Wasabi.

Data.World Chooses Precog To Deliver Faster, Easier Integrations To Virtually Any Data Source
By integrating Precog technology into its platform, data.world customers can now integrate with virtually any data source with stronger support for JSON, Parquet, and other semi-structured and file-based data sources.
Alteryx Macro for Massive Complex Data Sets
Are you trying to work with huge complex data sets in Alteryx Designer? Would you like to? Would you like to increase processing performance of Designer by 100x for many data sets? Would you like to be able to connect to live data sources like API’s or MongoDB?? Then the Precog Macro for Alteryx Designer can help.

New Rules for Modern Data
The new world of data has new rules that might seem scary at first, but it doesn’t have to be that way. The trick is to use a tool — like Precog — explicitly designed for the world where data is messy, experts are expensive, and agility is vital.

Precog Enables Tableau Customers to Access 1000s More Data Sources
The latest release of Precog AI-powered Data Loader has enhanced support for Tableau and Tableau Data Prep, allowing end users unprecedented access to 1000s more data sources.

Introduction to JSON and NoSQL data
JSON and NoSQL datasets come in many forms. Some datasets are essentially tabular. Others are complex multidimensional structures.

Precog Partners with SME
Precog, the company behind the popular Precog solution for transforming and loading complex data for analytics and data science, has partnered with SME Solutions Group, Inc. based in Tampa, Florida.

AI for Data Integration
What is AI for Data Integration? It’s really about understanding the relationships between the data regardless of structure, and above…
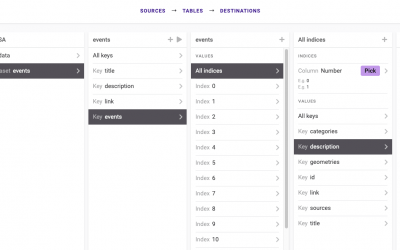
Precog: Uniform Access to Any API
Precog provides a single solution for streaming API data from the source, transforming it into analytics-ready tables, and loading it into your target destination.
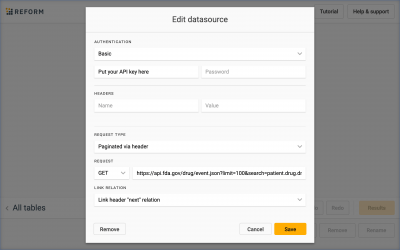
JSON to Insights: Tabulating Non-tabular Data with Precog
With Precog, we connect directly to the source of the data. In this case the source is the FDA.gov Web API. This ensures that we are always working with the latest data including new records and corrections.

JSON to Insights: Analysing Non-tabular Healthcare Data
This article follows in Keshav’s footsteps, showing how to derive insights from JSON healthcare data using Snowflake and Precog.
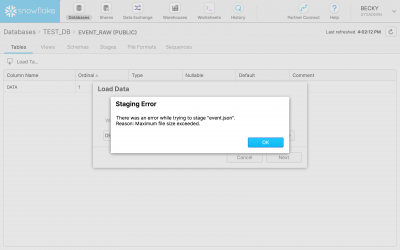
JSON to Insights: Tabulating Non-tabular Data Without Precog
Precog empowers even non-technical users to easily browse and curate tables from non-tabular data and load these tables directly into software such as Power BI and Tableau, databases such as Postgres and warehouses such as Snowflake.
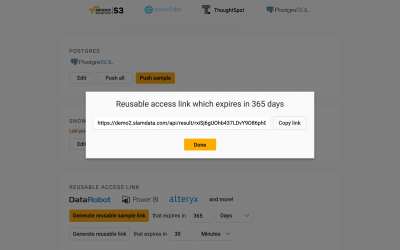
JSON to Insights: Analysing the Tabulated Data with Power BI
Now that the data has been tabulated, we can analyse it using software such as Microsoft Power BI.
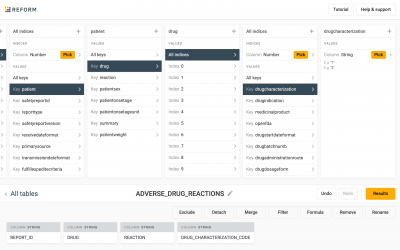
JSON to Insights: Joining Datasets with Precog
Precog shows us that in the adverse events dataset, drug characterizations are denoted as numbers. These numbers represent whether or not the drug was suspected as causing the adverse reaction or interacting with a suspected drug.

JSON to Insights: Analysing the Tabulated Data with SQL
Using Precog we can push the tabulated data into SQL databases and warehouses such as Snowflake and Postgres.

JSON to Insights: More Details About Precog
Tables in Precog are streaming and virtualised. We can think of this as though the Precog table were a grocery list rather than the groceries themselves. We can use the same list in different stores the same way we can use the same Precog table with different datasets. We can also export tables and import them into different copies of Precog.
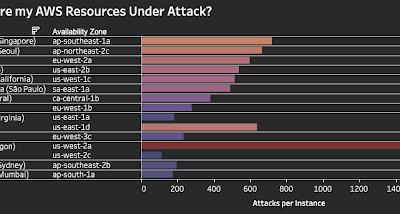
AWS GuardDuty Security Dashboard
Engineered to transform variable, complex JSON data, Precog draws source data from file output, API URLs, and data repositories such as AWS S3 and Azure Blob Storage.
Ingesting JSON as Analytic Ready Tables into SQL Server Using Precog and Azure Data Factory
The Precog solution enables data analysts and engineers to access complex JSON data as tables. In many cases we want those tables to be stored in Microsoft SQL Server or some other SQL database engine. Such requirement can be implemented easily using Precog and Azure Data Factory.

Data Science On JSON Using Precog Precog and RStudio or Jupyter Notebooks
Whether you’re a professional data scientist or studying to become a data scientist, you’ll likely need to work with a JSON dataset. JSON isn’t easy to work with. It’s not tabular, and you can’t just push it to a SQL database — at least not without a “bit” of work.
Turn any API Into An Analytic Ready Data Source
There are over 200,000 API?s on the web today, and more being added all the time. And the vast majority of these API?s provide JSON data via a REST interface. Unless you are a developer you generally can?t do much with this data or get any value from it. API?s are by design built for developers.

Reinventing ETL On A New Mathematical Foundation
The Multidimensional Relational Algebra, or MRA, is at the core of everything we do at Precog. It’s what enables our product to provide such a smooth and intuitive user experience.

Why Organizations Want To Solve The JSON Problem
JSON stands for JavaScript Object Notation, and it?s a way to format data. It was developed in the early 2000s, but it?s only in the last few years that it?s really caught on. JavaScript spec now includes a JSON object, and many developers are incorporating JSON as a sort of subset of the language itself.

What To Do When You Don’t Have A Data Integration Engineer
You’ve probably been hearing about “big data” for a while now ? the term has been around for years, and in the meantime, data has only gotten bigger. A whole industry has sprung up around it, from collection to storage to analytics, and data integration engineers are part of that puzzle. But what if your company doesn’t have one?

The Final Frontier? The Missing Link In ETL/ELT
The ETL (extract, transform, load) industry has been around for decades. Its primary purpose is to move data from source locations to data warehouses so analytics and data science teams can access the data in one place and perform analysis across a range of critical data sources.